13 Analytical Functions and Common Table Expressions
13.1 Module Introduction
This module explores advanced SQL features for analytical reporting: window functions and common table expressions (CTEs). Using the STUDENT schema, you will learn to rank, compare, and partition rows in ways that go beyond the capabilities of traditional aggregate functions.
13.2 Explanation
13.2.1 The OVER Clause
In SQL, an OVER clause is similar to our concept of a group from earlier. It is a way of selecting some collection of rows, over which you will calculate some value.
The main difference between the OVER AND GROUP BY clause is that an OVER clause calculates a value for every input row. We can essentially calculate groups or windows, and then broadcast the values back out to our original data structure.
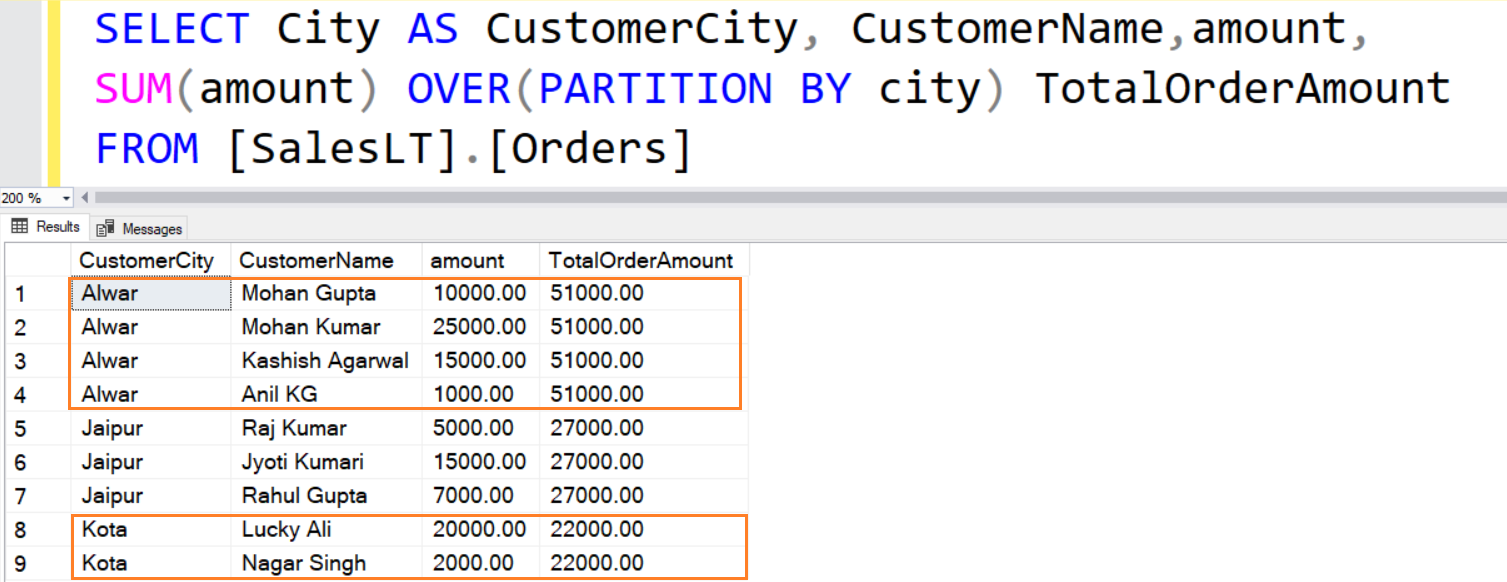
Consider the visual below. In this case, the total order amount is similar to the result of a GROUP BY aggregation. However, instead of calculating this value and joining it back to our original table, we can do the entire process by using an OVER clause.
13.2.2 PARTITION BY, and ROWS BETWEEN
The PARTITION BY clause divides the result set into groups to which the window function is applied. ROWS BETWEEN defines the frame within each partition.
Example: 3-row moving average of numeric_grade:
SELECT student_id, section_id, numeric_grade,
ROUND(AVG(numeric_grade) OVER (
PARTITION BY section_id
ORDER BY numeric_grade
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
), 1) AS moving_avg
FROM grade;This query calculates a moving average that includes the current row plus one row before and after, partitioned by section.
Reference: Lab 17.1
13.2.3 Window Functions: RANK, LAG, LEAD
Window functions compute results across a “window” of rows related to the current row, without collapsing the result set.
RANK assigns the same rank to tied rows and leaves gaps in ranking:
SELECT student_id, section_id, numeric_grade,
RANK() OVER (PARTITION BY section_id ORDER BY numeric_grade DESC) AS rank_in_section
FROM grade;This query ranks students by their numeric grade within each section, with the highest grades receiving rank 1.
LAG returns the value of a column from a previous row:
SELECT student_id, section_id, numeric_grade,
LAG(numeric_grade) OVER (PARTITION BY section_id ORDER BY numeric_grade) AS previous_grade
FROM grade;This query shows each grade along with the previous (lower) grade within the same section.
LEAD retrieves the value from a subsequent row:
SELECT student_id, section_id, numeric_grade,
LEAD(numeric_grade) OVER (PARTITION BY section_id ORDER BY numeric_grade) AS next_grade
FROM grade;This query shows each grade along with the next (higher) grade within the same section.
Reference: Lab 17.1
13.3 Exercises
Rank students by grade List
student_id,section_id, andnumeric_gradefrom theGRADEtable with a rank by section (useRANK).Find previous grade Use the
GRADEtable andLAGto show the prior student’s grade (ordered by grade) for each section.Find next grade Use the
GRADEtable andLEADto display the next student’s grade for each section.Moving average by section Show
student_id,numeric_grade, and the moving average of grade within the same section from theGRADEtable usingROWS BETWEEN.CTE for students with perfect grades Use a
WITHclause on theGRADEtable to find students who earned a grade of 100. Then join withSTUDENT,ENROLLMENT,SECTION, andCOURSEtables to display their full name and course description.Chained CTEs for average grades First, define a CTE using the
GRADEtable for average grade by section rounded to two places. Then, in the main query, filter for averages above 85 and join withSECTIONandCOURSEtables.
13.4 Q&A
Use the following questions to guide class discussion or individual reflection after completing the exercises:
- When would you use
RANKinstead ofROW_NUMBER, and what difference does it make for tied values? - Can you think of a real-world example where
LAGorLEADwould be critical for analysis? - How does using
PARTITION BYaffect the behavior of window functions compared to not using it? - Why might someone choose to use
ROWS BETWEENinstead of a simplerAVG()grouped by section? - What are some advantages of using CTEs (
WITHclauses) instead of subqueries? - How could chained CTEs improve the readability of a multi-step analytical query?
- What are the limitations of window functions? Are there any operations they cannot perform that require joins or subqueries instead?
13.5 Answers
1.
SELECT student_id, section_id, numeric_grade,
RANK() OVER (PARTITION BY section_id ORDER BY numeric_grade DESC) AS rank_in_section
FROM grade;2.
SELECT student_id, section_id, numeric_grade,
LAG(numeric_grade) OVER (PARTITION BY section_id ORDER BY numeric_grade) AS previous_grade
FROM grade;3.
SELECT student_id, section_id, numeric_grade,
LEAD(numeric_grade) OVER (PARTITION BY section_id ORDER BY numeric_grade) AS next_grade
FROM grade;4.
SELECT student_id, section_id, numeric_grade,
ROUND(AVG(numeric_grade) OVER (
PARTITION BY section_id
ORDER BY numeric_grade
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
), 1) AS moving_avg
FROM grade;5.
WITH perfect_scores AS (
SELECT student_id, section_id FROM grade WHERE numeric_grade = 100
)
SELECT s.first_name, s.last_name, c.description
FROM perfect_scores ps
JOIN student s ON ps.student_id = s.student_id
JOIN enrollment e ON s.student_id = e.student_id AND ps.section_id = e.section_id
JOIN section sec ON e.section_id = sec.section_id
JOIN course c ON sec.course_no = c.course_no;6.
WITH avg_grades AS (
SELECT section_id, ROUND(AVG(numeric_grade), 2) AS avg_grade
FROM grade
GROUP BY section_id
),
filtered AS (
SELECT * FROM avg_grades WHERE avg_grade > 85
)
SELECT f.section_id, f.avg_grade, c.description
FROM filtered f
JOIN section s ON f.section_id = s.section_id
JOIN course c ON s.course_no = c.course_no;